Ubiquiti EdgeRouter X vs. MikroTik hEX
Da ich auch mal Router testen wollte und den EdgeRouter X (ER-X) eh schon besitze, habe ich mir ein vergleichbares Gerät von MikroTik besorgt, den hEX bzw. den RB750Gr3 (dritte Generation des hEX).
MikroTik ist ein Netzwerkausrüster aus Lettland. Wie Ubiquiti bieten sie professionelle Netzwerk-Hard- und Software zu bezahlbaren Preisen an. Man kann sogar Einzelteile wie Boards, Ports, Gehäuse usw. einzeln kaufen und sich damit seinen Traum-Router zusammenbauen.
Die Kontrahenten
Sie könnten zwar von außen nicht unterschiedlicher sein, ihre inneren Werte sind jedoch sehr vergleichbar. Beide bieten fünf Gigabit-Ports und können an Port 1 über 24 V Passive PoE mit Strom versorgt werden. Außerdem nutzen beide den gleichen SoC von MediaTek und damit die gleiche CPU: einen 880 MHz MIPS Dual Core (4 Threads). Preislich liegen sie mit ca. 55 - 60 Euro natürlich auch gleich auf.
Ubiquiti EdgeRouter X

Putzig, was? Der ER-X ist wirklich klein, aber davon sollte man sich nicht täuschen lassen. Er bietet fünf völlig frei konfigurierbare Gigabit-Ports. Einmal WAN, einmal LAN und drei Switch-Ports mit separatem Netz? Kein Problem. Zweimal WAN mit automatischem Fail Over? Klar. Reiner Switch-Betrieb? Und ob, auch wenn er alleine dafür zu schade ist.
Auf dem ER-X läuft eine Linux-Distribution namens EdgeOS, die auch auf allen weiteren EdgeMAX-Geräten von Ubiquiti eingesetzt wird. Auf Einschränkungen im Vergleich zu den größeren Brüdern verzichtet man dankenswerterweise.
EdgeOS bietet ein recht umfangreiches Web-Interface mit dem sich viele Aufgaben schnell und einfach erledigen lassen. Für die wichtigsten Standard-Anwendungsfälle stehen Assistenten (Wizards) bereit. Ein simples Setup für WAN mit vier LAN-Ports als Switch und PPPoE inkl. Firewall ist damit in einer Minute erledigt. IPv6 wird leider bisher vom Web-Interface kaum unterstützt, bis auf eine Option in den Wizards für ein Standard-Setup mit Firewall, das aber ohne weitere manuelle Konfiguration nicht funktioniert, kann es nur noch IPv6-Adressen für die Interfaces anzeigen.
Alles weitere inkl. der tiefgreifenderen Konfigurationsmöglichkeiten muss über das CLI erledigt werden. Klingt nun schlimmer als es ist. EdgeOS basiert auf Vyatta, einer Linux-Distribution speziell für Netzwerkgeräte. Vyatta hat ein übersichtliches, recht einfach zu erlernendes Interface. Änderungen werden nicht sofort aktiv, erst nachdem man den Befehl commit abgeschickt hat werden sie aktiv aber noch nicht gespeichert. Sollte man sich also z.B. mal bei einer Firewall-Änderung aussperren, reicht ein Neustart des ER-X und alles läuft wie zuvor. Um zu speichern wird der Befehl save genutzt.
Man muss also keine Angst vor dem CLI haben. Kaputt machen kann man nichts, sofern man nicht gleich jede Änderung speichert.
Zusätzlich bietet der EdgeRouter X via CLI zuschaltbare Hardware-Beschleunigung für NAT und IPsec (aktuell Beta). Lt. eines Mitarbeiters auf Reddit überlegt Ubiquiti derzeit außerdem Deep Packet Inspection (DPI) in Hardware zu unterstützen – da fehlt wohl noch ein passender Treiber. Damit wäre er fast auf dem Niveau des nächst größeren Bruders, dem EdgeRouter Lite (ca. 90 - 100 Euro).
MikroTik hEX

Zugegeben, das Gehäuse wirkt im Vergleich zum ER-X etwas billig, es stört aber auch nicht. Ich habe jedenfalls noch niemanden gesehen, der Router wegen ihres Gehäuse-Designs kauft. Die Metallhülle des ER-X mag Hitze besser ableiten, aber da beide Geräte nicht sonderlich heiß werden, spielt das eine untergeordnete Rolle.
Die Ports lassen sich genauso frei konfigurieren wie bei der Konkurrenz. Selbst Port Mirroring in Hardware ist möglich, was meines Wissens nach aktuell beim ER-X nur via Software geht.
Zusammen mit dem hEX kommt eine Lizenz für RouterOS, MikroTiks Gegenstück zu EdgeOS. Es kann allerdings auch separat lizenziert und auf x86-Hardware betrieben werden. Wer sich das Web-Interface (WebFig) vorab ansehen möchte, kann das hier tun.
Der hEX wird vorkonfiguriert geliefert: WAN liegt auf Port 1, die restlichen Ports sind dem Switch zugeordnet. Ein DHCP-Server, DNS-Forwarding usw. sind bereits eingerichtet. Assistenten für andere Konfigurationen gibt es aber nicht. Wenn man lieber selbst Hand anlegen möchte, besteht beim ersten Login die Möglichkeit einfach per Klick alle vordefinierten Einstellungen zurückzusetzen.
WebFig ist standardmäßig an LAN-Port 2 über die IP-Adresse 192.168.88.1 erreichbar. Alternativ bietet MikroTik mit WinBox ein Windows-Programm, das wie eine Art Wrapper für WebFig aussieht, sich aber durch Fenster-Unterstützung innerhalb der Software besser und schneller bedienen lässt. Für Mac-User gibt es WinBox inkl. Wine als fertiges Bundle – funktioniert bei mir bisher problemlos.
Im Gegensatz zum Web-Interface von EdgeOS kann WebFig alle Funktionen konfigurieren. Über einen Paket-Manager lassen sich außerdem weitere Möglichkeiten nachrüsten, u.A. IPv6, das als inaktives Paket mitgeliefert wird.
Die Oberfläche erschlägt einen auf den ersten Blick durch die vielen Optionen und ist etwas gewöhnungsbedürftig, wenn man vorher nur mit EdgeOS zu tun hatte. Nach ein paar Problemen komme ich aber mit WebFig ziemlich gut klar. Die grundsätzlichen Vorgänge unterscheiden sich ja nicht. Umgekehrt ist sicherlich auch EdgeOS für einen MikroTik-Nutzer erstmal sehr ungewohnt.
Das CLI von RouterOS ist ebenso logisch und einfach strukturiert wie in EdgeOS, auch wenn natürlich die Syntax anders aussieht. Änderungen sind im Gegensatz zu EdgeOS sofort aktiv und werden direkt gespeichert. Um Probleme zu verhindern, bietet RouterOS den Safe Mode für das CLI und WebFig. Darin gemachte Änderungen werden auch sofort umgesetzt, aber erst gespeichert, wenn man das entsprechende Kommando gibt. Im Zweifelsfall reicht ein Neustart und nichts ist passiert.
In Sachen Hardware-Beschleunigung zeigt sich der hEX knausriger als der ER-X, da aktuell nur IPsec unterstützt wird. Ob da weitere Planungen anstehen, konnte ich leider nicht in Erfahrung bringen. Bleibt die Frage, ob das überhaupt geht? Offiziell unterstützt der SoC beider Geräte nur Hardware-IPsec. Es ist also wahrscheinlich, dass der ER-X zusätzliche Hardware für NAT und DPI besitzt.
Benchmark
Mein Benchmark-Szenario basiert auf iPerf3 mit einer, zehn und 100 gleichzeitigen TCP-Verbindungen und ist damit eher theoretischer Natur. Einen ausgefeilten Test mit zigtausenden HTTP-Downloads in verschiedenen Größen wie Ars Technica kann ich leider derzeit nicht bieten. Vielleicht sollte ich “routerperf” entwickeln. :D
Der Benchmark fand zwischen meinem PC und dem MacBook Pro statt. Der Windows-Rechner verfügt über eine Intel-LAN-Schnittstelle, während der Mac über einen Thunderbolt-Ethernet-Adapter mit dem LAN verbunden war. Sind also beides keine Krücken.
Als Referenzwerte dienen Durchläufe an beiden Rechnern, die über einen Cisco SoHo-Switch verbunden waren.
In allen anderen Szenarien war der Mac als Server am WAN-Port des jeweiligen Routers und der PC am entsprechenden LAN-Port in einem separaten Netz. Das NAT findet via Masquerading in IPTables statt.
Ergebnis
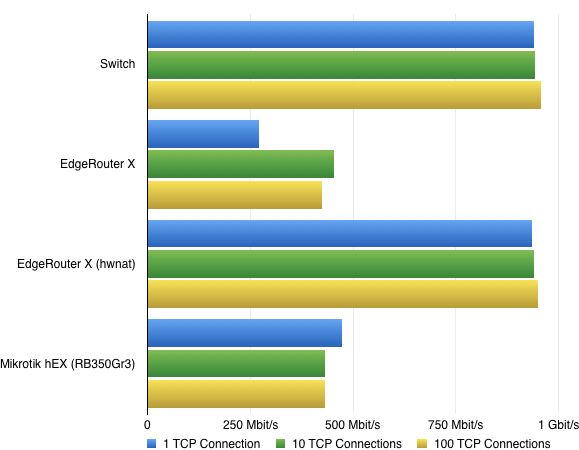
Das Hardware-NAT des ER-X schlägt richtig ein, während die Leistung ohne Hardware-Unterstützung ungewöhnlich inkonsistent ist. Das volle Potenzial wird erst mit mehreren Verbindungen wirklich genutzt. Der hEX dagegen skaliert in dieser Situation wie man es erwartet.
Da beide die gleiche CPU verwenden ist das Ergebnis bei nur einer Verbindung umso erstaunlicher. Es wäre durchaus möglich, dass es sich hier um einen Bug handelt. Ein ähnliches Problem gab es im Sommer mit dem UniFi Security Gateway, das auf der Hardware des EdgeRouter Lite basiert.
In der Realität dürfte die Differenz zwischen dem hEX und ER-X ein Stück kleiner ausfallen, denn nicht jede Verbindung läuft über TCP und die Paketgröße hat hier auch ein Stück mitzureden.
Fazit
Ich bin mit beiden Geräten sehr zufrieden. Für knapp 60 Euro bekommt man in beiden Fällen ein überzeugendes Produkt, das auch gehobenen Ansprüchen im Heimnetz mehr als gerecht wird.
Nur wer sich glücklich schätzen kann eine Gigabit-Internetverbindung zu besitzen, dürfte mit dem ER-X die schlauere Wahl treffen – auch wenn in der Realität der Unterschied geringer ausfallen wird. Ganz nebenbei: der hEX hat natürlich auch größere Brüder.
Letztendlich dürfte es für die meisten von uns eine reine Geschmacksfrage sein. Ich werde beide im Wechsel einsetzen und die Entwicklung beobachten. Da beide praktischerweise 24 V Passive PoE unterstützen, lassen sie sich sehr einfach tauschen. Kabel bei einem abstecken, beim anderen anstecken – fertig.